Using Compressed JSON Data With Amazon Athena
Amazon Athena pricing is based on the bytes scanned. That is a little ambiguous. To clarify, it’s based on the bytes read from S3. It’s not based on the bytes loaded into Athena.
So, you can reduce the costs of your Athena queries by storing your data in Amazon S3 in a compressed format.
In our previous article, Getting Started with Amazon Athena, JSON Edition, we stored JSON data in Amazon S3, then used Athena to query that data.
In this article, we will compress the JSON data, and compare the results.
Our Input Data
Like the previous article, our data is JSON data. One record per file. One record per line:
{ "name": "Albert", "numPets": 1, "birthDate": "1970-01-01 07:20:00", "LargeDataItem": "..." }
The difference this time is that we are compressing the data using GZIP before placing the data in S3.
Note, in the previous article, our JSON data was not compression-friendly. For example, the original JSON file was 73 bytes. Compressing using GZIP resulted in a .json.gz file of 97 bytes. It simply was too small to compress. For this reason, and for the purposes of this demonstration, we are adding more, unnecessary data to our JSON data so that it will be smaller when compressed. Examine your own JSON data to determine whether compression results in smaller files or not.
Like last time, we placed the data files in our S3 bucket in a flat list of objects without any hierarchy. Here are our uncompressed files:
$ aws s3 ls s3://athena-testing-1/Uncompressed/
2016-12-19 18:57:20 2907 Uncompressed/Data1.json
2016-12-19 18:57:20 2906 Uncompressed/Data2.json
2016-12-19 18:57:20 2908 Uncompressed/Data3.json
2016-12-19 18:57:20 2907 Uncompressed/Data4.json
2016-12-19 18:57:20 2905 Uncompressed/Data5.json
Here are our compressed files:
$ aws s3 ls s3://athena-testing-1/Compressed/
2016-12-19 18:57:42 1258 Compressed/Data1.json.gz
2016-12-19 18:57:42 1260 Compressed/Data2.json.gz
2016-12-19 18:57:42 1261 Compressed/Data3.json.gz
2016-12-19 18:57:42 1261 Compressed/Data4.json.gz
2016-12-19 18:57:42 1257 Compressed/Data5.json.gz
And we can confirm that the compressed JSON data is smaller than the uncompressed JSON data.
Creating the Tables
We are going to create 2 tables: one for the uncompressed data, and one for the compressed data. Creating the table for compressed data is the same as creating a table for uncompressed data. We used the following SQL script to create our uncompressed data table:
CREATE EXTERNAL TABLE IF NOT EXISTS TestDb.UncompressedTable1 (
`name` string,
`numPets` int,
`birthDate` timestamp
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://athena-testing-1/Uncompressed/'
And we used the following SQL script to create our compressed data table:
CREATE EXTERNAL TABLE IF NOT EXISTS TestDb.CompressedTable1 (
`name` string,
`numPets` int,
`birthDate` timestamp
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://athena-testing-1/Compressed/'
Other than the table name and location in S3, the scripts are identical.
Querying the Data
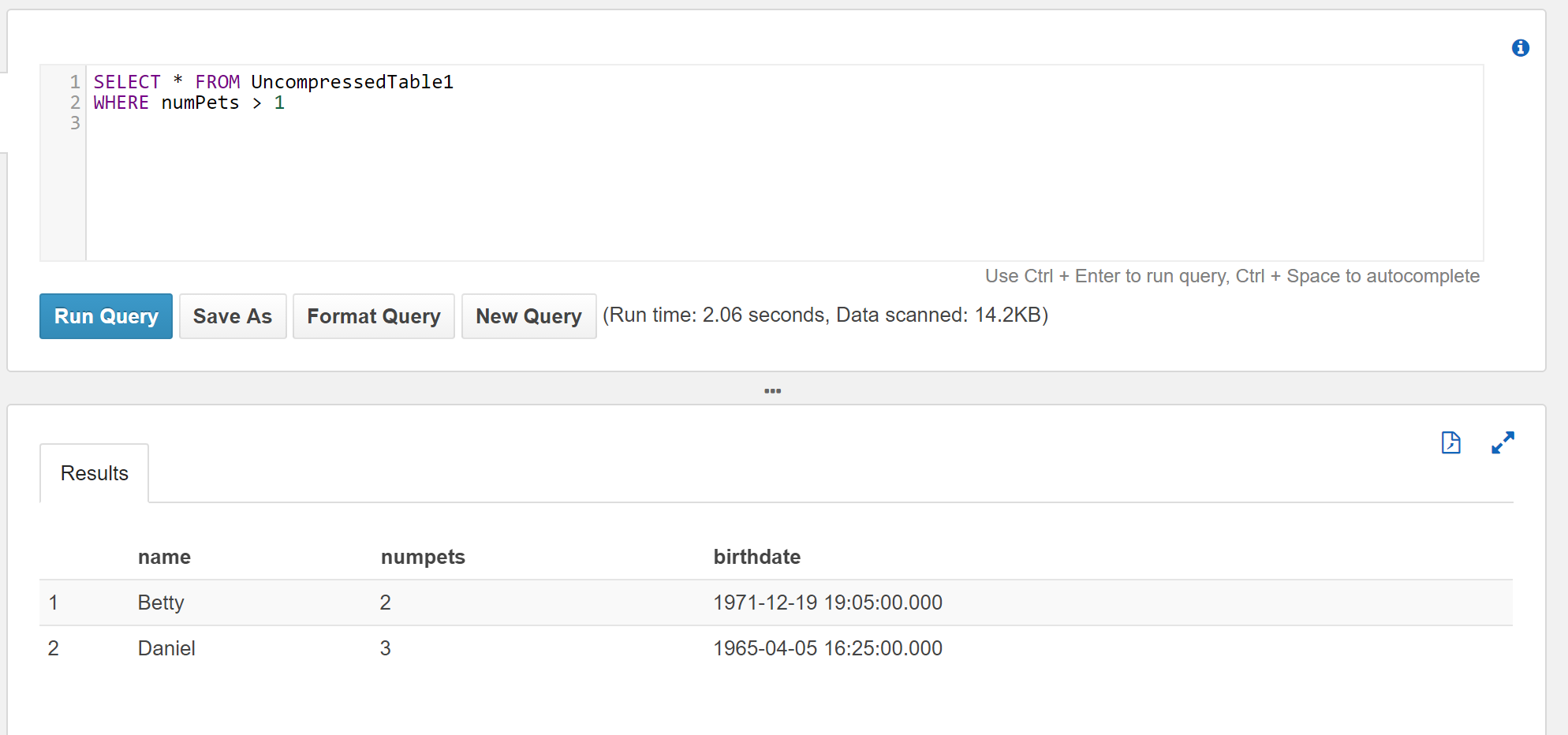
With our tables in place, we can execute a SELECT query against the uncompressed data:
SELECT * FROM UncompressedTable1
WHERE numPets > 1
Now, executing the same query against the compressed table:
SELECT * FROM CompressedTable1
WHERE numPets > 1

Notice the results from the queries are the same. But the data scanned when querying the compressed data is significantly less than the data scanned when querying the uncompressed data.
| Table | Rows Returned | Data Scanned |
|---|---|---|
| UncompressedTable1 | 2 | 14.2 KB |
| CompressedTable1 | 2 | 6.15 KB |
TL;DR
If your JSON data can be compressed, then do so before putting the data in S3. Even if it’s a simple GZIP compression. Not only will your basic S3 costs be lower, but your Athena queries will scan less data, which can result in lower costs.
Next, we’ll take a look at partitioning your data to help reduce the amount of data scanned even more.
Articles In This Series
- Getting Started with Amazon Athena, JSON Edition
- Using Compressed JSON Data With Amazon Athena
- Partitioning Your Data With Amazon Athena
- Automatic Partitioning With Amazon Athena
- Looking at Amazon Athena Pricing
About Skeddly
Skeddly is the leading scheduling service for your AWS account. Using Skeddly, you can:
- Reduce your AWS costs,
- Schedule snapshots and images, and
- Automate many DevOps and IT tasks.
Sign-up for our 30 day free trial or sign-in to your Skeddly account to get started.